1. 관계 데이터 연산
1) 데이터모델 : 데이터 구조 + 연산 + 제약조건
2) 관계 데이터 연산
-관계 데이터 모델의 연산
-원하는 데이터를 얻기 위해 릴레이션에 필요한 처리 요구를 수행
-관계 대수와 관계 해석으로 분류, 기능과 표현력 측면에서 능력은 동등
3) 관계 대수와 관계 해석
(1)관계 대수
-데이터 처리 과정을 순서대로 기술
-절차언어
-릴레이션을 처리하는 연산자들의 모임 : 일반 집합 연산자와 순수 관계 연산자로 분류
-폐쇄 특성 (Closure property) 이 존재 : 피연산자 = 연산결과 = 릴레이션
(2)관계 해석
-처리를 원하는 데이터가 무엇인지 기술
-비절차언어
-투플 관계 해석
-도메인 관계 해석
2. 관계 대수 : 일반 집합 연산자
1) 일반 집합 연산자 : 릴레이션이 투플의 집합이라는 개념을 이용한 연산자
2) 일반 집합 연산자의 특성
-2개의 릴레이션 대상 연산
-합병 가능 조건을 만족 = 두 릴레이션의 차수와 도메인이 같아야 함
3) 합집합(Union)
- 두 릴레이션 R, S 의 합집합
-결과 릴레이션의 카디널리티는 릴레이션 R 과 S 의 카디널리티를 더한것 보다 같거나 적음
-교환적, 결합적 특징
4) 교집합(Intersection)
-두 릴레이션 R,S의 교집합
-결과 카디널리티는 릴레이션 R과 S의 어떤 카디널리티보다 크지 않음
-교환적, 결합적 특징
5) 차집합(Difference)
-두 릴레이션 R,S의 차집합
-R-S 의 카디널리티는 릴레이션 R의 카디널리티와 같거나 적음
- 교환적, 결합적 특징
6) 카티션 프로덕트(Cartesian product)
-두 릴레이션 R,S의 카디널 프로덕트 $R\times S$
-릴레이션 R에 속한 투플과 릴레이션 S에 속한 투플을 모두 연결하여 새로운 투플로 결과 릴레이션 구성
-결과 카디널리티는 카디널리티 R과 S의 카디널리티를 곱한 것과 같음
-차수는 릴레이션 R과 S의 차수를 더한 것과 같음
-교환적 , 결합적 특징

3.관계 대수 : 순수 관계 연산자
1) 순수 관계 연산자 : 릴레이션의 구조와 특성을 이용하는 연산자
2) 셀렉트(Select)
- 조건을 만족하는 투플만 선택하여 결과 릴레이션 구성
-하나의 릴레이션으로 연산수행
- 수학적 표현법 : $\sigma _{조건식}(릴레이션)$
- 데이터 언어적 표현법 : 릴레이션 where 조건식
-조건식은 비교, 논리 연산자 이용해 작성
-결과 릴레이션은 연산 대상 릴레이션의 수평적 부분집합
- 교환적 특징 있음
ex) $\sigma _{등급='gold'}(고객)$
고객 where 등급 = 'gold'
3) 프로젝트 (Project)
-릴레이션에서 선택한 속성 값으로 결과 릴레이션 구성
-하나의 릴레이션으로 연산
-수학적 표현법 : $\pi _{속성리스트}(릴레이션)$
- 데이터 언어적 표현법 : 릴레이션[속성리스트]
-결과 릴레이션에서 동일한 투플은 중복되지 않고 한번만 나타남
-결과 릴레이션은 연산 대상 릴레이션의 수직적 부분집합
ex) $\pi _{이름, 등급, 적립금}(고객)$
고객[이름, 등급, 적립금]
4) 조인(Join)
-두 릴레이션을 조합하여 결과 릴레이션 구성
-조인 속성 값이 같은 투플만 연결하여 생성된 투플을 결과 릴레이션에 포함
-표현법 : $릴레이션1 \bowtie 릴레이션2$
-자연조인이라고도 함 $\bowtie _{N}$


(1) 세타조인 (Theta join)
-자연 조인에 비해 더 일반화된 조인
-조인 조건을 만족하는 두 릴레이션의 모든 투플을 연결하여 결과 릴레이션 구성
-결과 릴레이션의 차수는 두 릴레이션의 차수 더한 것
-표현법: $릴레이션1 \bowtie _{A\theta B} 릴레이션2$ : $\theta $는 비교연산자 의미
(2) 동일 조인(Equi-join) : $\theta $ 연산자가 '=' 인 세타조인

(3) 세미조인 (Semi-join)
-릴레이션2를 조인 속성으로 프로젝트 연산 후 → 릴레이션1에 자연조인
-불필요한 속성을 미리 제거하여 비용 절감 장점
-교환적 특징 없음
-$R\propto S$
(4) 외부조인 (Outer join)
-자연 조인 연산에서 제외되는 투플도 결과 릴레이션에 포함시키는 조인
- $R \propto^+ S$


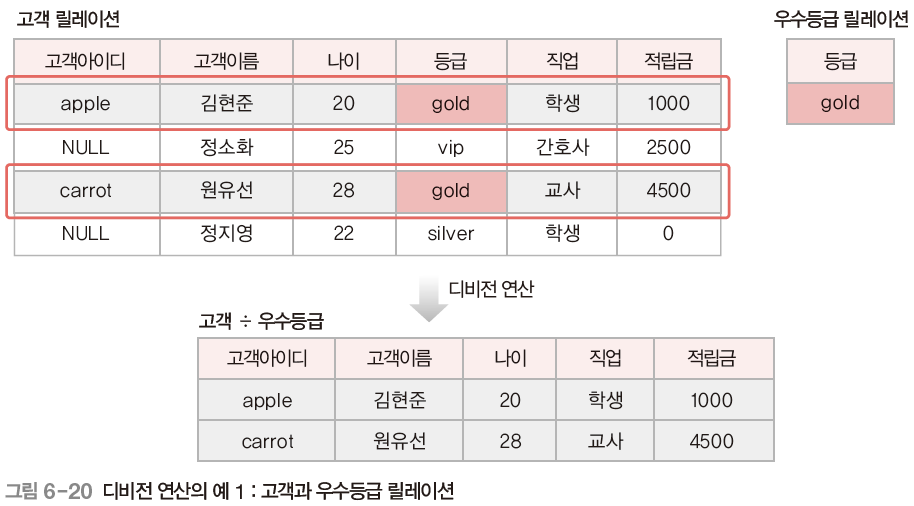
5) 디비전(Division)
-릴레이션2의 모든 투플과 관련된 릴레이션1의 투플로 결과 릴레이션 구성
-릴레이션 1이 릴레이션2의 모든 속성 포함 필요, 같은 도메인이어야 함
-표현법 : 릴레이션 1 ÷ 릴레이션 2

'School Activities > Database' 카테고리의 다른 글
| 관계 데이터 모델 (0) | 2019.10.14 |
|---|---|
| 데이터 모델링 (0) | 2019.10.14 |
| 데이터베이스시스템 (0) | 2019.10.14 |
| 데이터베이스관리시스템 (0) | 2019.10.13 |
| 데이터베이스 기본개념 (0) | 2019.10.13 |